




In a large-scale study of active working open source projects we have found an average comment density of about 20% (= one comment line in five code lines). Given that much of open source remains volunteer work, we believe that a comment density of 20% represents the sweet spot of code commenting in open source projects: Neither are you over-documenting your code and hence wasting resources, nor are you under-documenting and thereby endangering your project.
This statement is based on the argument that programmers only document as much as necessary, but not more. Since open source remains merit-driven, usually no single person can order you to document more (or less), and a comment density of 20% on average seems to be were most projects end up naturally. This argument is further supported by the analysis provided below. This analysis shows how the comment density is largely independent of other variables like project or team size and is only slowly decreasing as a project matures.
Comment Density
Figure 1 gives the overall picture. Each data point (dot) represents one project and its comment density. The comment density across all 5000 projects averages to about 18.7%.
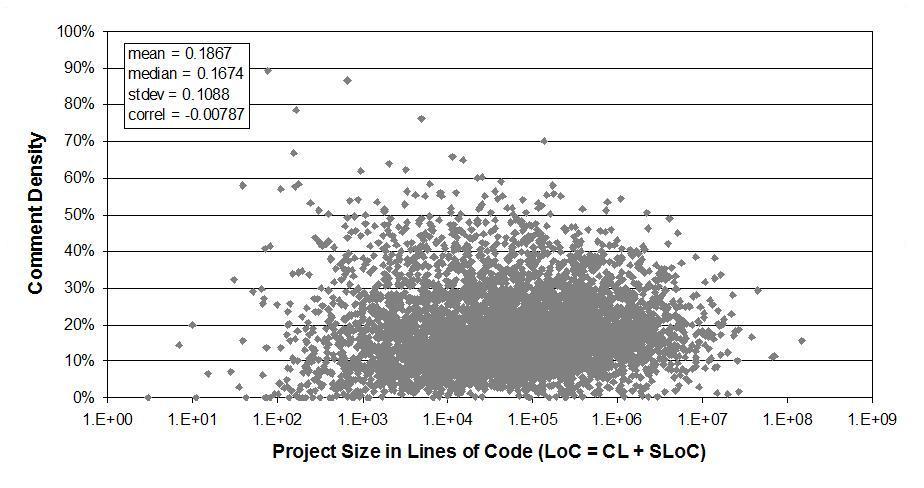
Figure 2 reviews comment density by size of commit (code contribution). As can be seen, smaller commits have a higher than average comment density. In particular, a commit of one source code line comes with two comment lines, and a commit of two source code lines also comes with two comment lines.
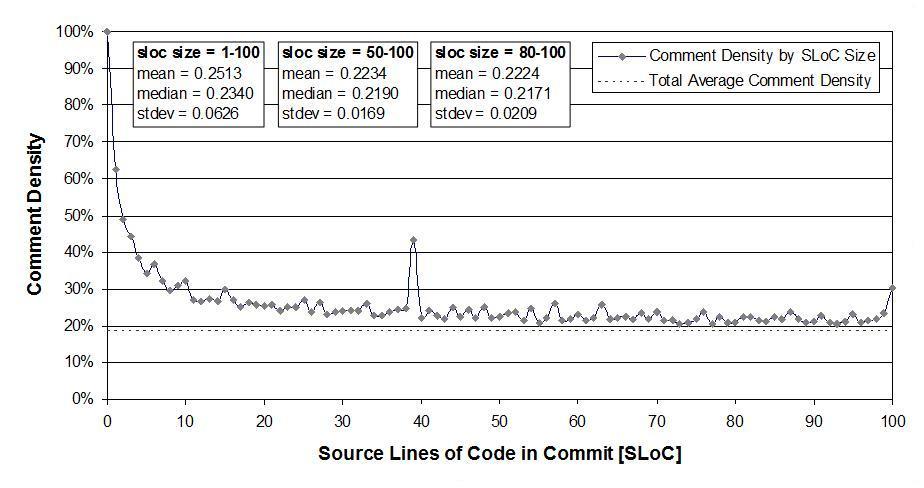
Figure 3 shows how comment density varies by team size (number of committers). As can be seen, it does not vary (fluctuation only gets higher with larger team sizes, of which there are less and less). Comment density and team size are not correlated at all! The same applies to project size (not shown).
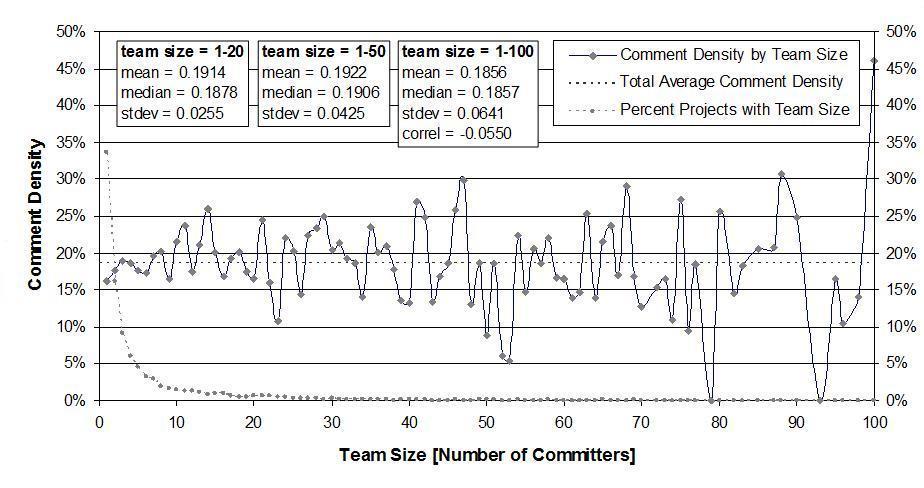
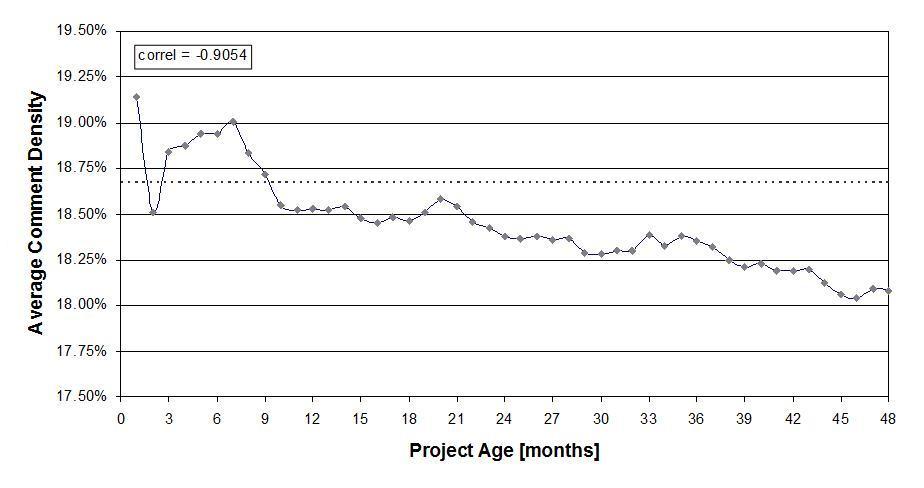
Figure 4 finally shows how comment density varies by project age. There is a correlation, and comment density goes down as a project gets older. Basically, it appears that with a maturing project, developers document less. Please note, however, that the actual decline in comment density, while statistically significant, is quite small and may not matter in the grand scheme of things.
Please refer to the accompanying four-page research paper for more details. I understand that much more needs to be said. You may also like the prior post on how open source comments, by programming language.
The data used in this analysis was provided by Ohloh.net.
Science Soapbox
We had originally submitted a much more detailed analysis to ICSE 2009. Unfortunately, the submission got rejected, and even the referenced four-pager almost didn’t make it. This is because, as one reviewer put it, “this work has no merit, because it only measures [open source projects].” This comment still annoys me, because of its warped understanding of science. What are we supposed to do, if not measure the real world? Freely phantasize about how software development works? Next time you hear some wild claims about how software development supposedly works, please ask the presenter what data or studies they base their work on.



Leave a Reply